


Columbia Mühendislik'ten bilgisayar bilimcileri, düz metin dosyalarının içine enformasyon gizlemek için yeni bir yöntem geliştirdiklerini duyurdu. Times New Roman ya da Helvetica gibi yazı tiplerinin harflerinin biçiminde gözle algılanamayacak denli küçük değişiklikler yapılmasına dayanan bu yeni teknik ile şifrelenmiş bir iletiyi çözmek için akıllı telefona yüklenebilen bir uygulama kullanmak yeterli oluyor. Yazılım, her harfin 52 farklı versiyonunu yaratabiliyor.
Chang Xiao, Cheng Zhang, Changxi Zheng adlı üç araştırmacıdan oluşan ekip, "FontCode" (Yazı Tipi Kodu) adını verdikleri tekniği, arXiv sitesinde yayımladıkları makalede şöyle özetliyor: "Metin dosyaları için bir enformasyon gömme tekniği olan FontCode'u sunuyoruz. Belirli yazı tipleri ile yazılmış bir metin belgesi verildiğinde, yöntemimiz metin içeriğini değiştirmeden, metni oluşturan karakterlerin oyuntularında hafif değişimler yaparak, kullanıcının belirlediği bilgiyi gömebiliyor. Bir yazı tipi dağıtıcısı üzerindeki her bir karakterin oyuntularını sürekli olarak değiştiren, daha önceden geliştirilmiş üretken bir modeli güçlendirerek, göze çarpmayan ama makine tarafından tanınabilir oyuntu değişimleri seçmek için bir algoritma geliştirdik. Ardından, kullanıcı tarafından verilen bir iletiyi metin belgesine gömen ve başlangıçtaki belgeden çok az değişik görünümde bir belge üreten bir algoritma ekledik. Ayrıca, vektör grafiği ya da piksel görüntüsü veya hatta basılı kağıt şeklinde saklanmış durumdaki kod içeren bir belgede gömülü olan bilgiyi yeniden oluşturabilen bir oyuntu tanıma yöntemi sunduk. Bunlara ek olarak, çok sayıda tanıma hatasını düzeltebilen yeni bir hata düzeltme kodlama şeması da sunduk. Son olarak, metin dosyası metadata saklayıcı, göze çarpmayan optik barkod, şifreli ileti gömme şeması ve metin belgesi imzası için kullanılabilecek olan tekniğimizin geniş bir uygulama alanı olduğunu gösterdik."
Ekibin usta üyesi Changxi Zheng, FontCode'un gizli ileti gönderme amaçlı kullanımın yanı sıra, şirketlerin işine yarayabilecek uygulamalarının da önemini vurguluyor: Belgelerin görüntüsü bozulmadan kullanım haklarının korunmasını, QR kodu veya başka metadata türlerinin gömülmesini sağlıyor. Bu teknikte bir metin belgesine gizlenebilecek veri miktarı, belgedeki metnin uzunluğuna bağlı oluyor. Çoğu yazı tipi ile kullanılabiliyor ve diğer belgeye veri gizleme yöntemlerinden farklı olarak çoğu belge tipi ile kullanılabiliyor. Ayrıca belgenin dosya türü değiştirilse ya da çıktısı alınsa bile gizli ileti yitirilmiyor. Fakat eğer şifreli metni bir editörde açıp kopyalarak, başka bir metin editörü penceresine yapıştırırsanız, iletiyi yitiriyorsunuz.
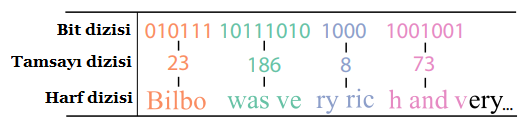 Program gizlenecek mesajı bir bit dizisine çevirdikten sonra, bir tamsayı dizisine çeviriyor. Her bir tamsayı, normal metindeki beş harflik bir bloğa atanıyor.
Program gizlenecek mesajı bir bit dizisine çevirdikten sonra, bir tamsayı dizisine çeviriyor. Her bir tamsayı, normal metindeki beş harflik bir bloğa atanıyor.
FontCode'u kullanarak veri gömmek için gizli bir ileti ve bir taşıyıcı belge veriyorsunuz. Program gizlenecek mesajı 0 ve 1'lerden oluşan bir bit dizisine (ASCII veya Unicode) çevirdikten sonra, bir tamsayı dizisine çeviriyor. Her bir tamsayı, normal metindeki beş harflik bir bloğa atanıyor. Daha sonra normal metindeki her bir harfin yerine, kod kitabındaki değiştirilmiş hâli yerleştiriliyor. Her beşlideki değiştirilmiş hâldeki harflerin kod kitabındaki konum numaralarının toplamı, o beşliye atanmış olan tamsayı ediyor.
Gizli iletiyi açığa çıkarmak için ise işlem tersinden yapılıyor. Dijital bir dosyadan veya akıllı telefon ile çekilmiş bir fotoğraftan, FontCode harfleri orijinalleriyle karşılaştırarak değiştirilmiş harfleri belirliyor ve kod kitabından iletiyi oluşturuyor.
Karşılaştırma, evrişimli sinirsel ağlar (İng. convolutional neural networks - CNN) kullanılarak yapılıyor. Vektör çizimli (PDF olarak kaydedilenler ya da Illustrator gibi programlarla hazırlananlar gibi olan) yazı tiplerinde söz konusu belirleme işlemi kolay, çünkü şekil ve yol tanımları bilgisayar tarafından okunabilir oluyor. Ama PNG, IMG gibi pikselli yazı tiplerinde iş o kadar basit değil. Aydınlatma farkı, değişik kamera açıları, gürültü ve netlikteki bozukluklar dolayısıyla karşılaştırma ve oyuntusu farklı olanları belirleme işlemi güçleşiyor.
 "Hello World" iletisinin "Bilbo was very rich..." şeklinde başlayan metnin içince gizlenme ve gizli metnin yeniden oluşturulma sürecini gösteren şema. "Hello World" iletisinin "Bilbo was very rich..." şeklinde başlayan metnin içince gizlenme ve gizli metnin yeniden oluşturulma sürecini gösteren şema.
"Hello World" iletisinin "Bilbo was very rich..." şeklinde başlayan metnin içince gizlenme ve gizli metnin yeniden oluşturulma sürecini gösteren şema. "Hello World" iletisinin "Bilbo was very rich..." şeklinde başlayan metnin içince gizlenme ve gizli metnin yeniden oluşturulma sürecini gösteren şema.
Ekip bu güçlüğü aşabilmek için 1700 yıllık Çinli Kalan Teoremi'nden yararlandıklarını belirtiyor. Bu teorem, bilinmeyen bir sayının, birkaç farklı bölenle bölümünden kalan sayılara bakarak bulunmasını sağlar. Efsaneye göre eski bir Çin hükümdarı, ordusundaki asker sayısını bulmak için tüm orduyu önce 3 kişilik, sonra 5 kişilik, sonra da 7 kişilik gruplara ayırır ve her seferinde grup dışı kalan asker sayısına bakarmış. Buna göre, ordudaki toplam asker sayısını hesaplarmış. Zheng, FontCode için bu teoremden nasıl yararlandıklarını şöyle anlatıyor: "Üç tane bilinmeyen değişken olsun. Üç tane lineer eşitlik ile bunların üçünü de bulabilmeniz gerekir. Eğer eşitlik sayısını üçten beşe çıkarırsanız, bu beş eşitlikten herhangi üçünü bildiğiniz sürece, üç bilinmeyeni yine bulursunuz." Çinli Kalan Teoremi'ni kullanarak, harflerdeki değişikliklerin %25'i tanınamasa bile iletilerin yeniden oluşturulabileceğini araştırmacılar gösterdi.
Chang Xiao, Cheng Zhang, Changxi Zheng adlı üç araştırmacıdan oluşan ekip, "FontCode" (Yazı Tipi Kodu) adını verdikleri tekniği, arXiv sitesinde yayımladıkları makalede şöyle özetliyor: "Metin dosyaları için bir enformasyon gömme tekniği olan FontCode'u sunuyoruz. Belirli yazı tipleri ile yazılmış bir metin belgesi verildiğinde, yöntemimiz metin içeriğini değiştirmeden, metni oluşturan karakterlerin oyuntularında hafif değişimler yaparak, kullanıcının belirlediği bilgiyi gömebiliyor. Bir yazı tipi dağıtıcısı üzerindeki her bir karakterin oyuntularını sürekli olarak değiştiren, daha önceden geliştirilmiş üretken bir modeli güçlendirerek, göze çarpmayan ama makine tarafından tanınabilir oyuntu değişimleri seçmek için bir algoritma geliştirdik. Ardından, kullanıcı tarafından verilen bir iletiyi metin belgesine gömen ve başlangıçtaki belgeden çok az değişik görünümde bir belge üreten bir algoritma ekledik. Ayrıca, vektör grafiği ya da piksel görüntüsü veya hatta basılı kağıt şeklinde saklanmış durumdaki kod içeren bir belgede gömülü olan bilgiyi yeniden oluşturabilen bir oyuntu tanıma yöntemi sunduk. Bunlara ek olarak, çok sayıda tanıma hatasını düzeltebilen yeni bir hata düzeltme kodlama şeması da sunduk. Son olarak, metin dosyası metadata saklayıcı, göze çarpmayan optik barkod, şifreli ileti gömme şeması ve metin belgesi imzası için kullanılabilecek olan tekniğimizin geniş bir uygulama alanı olduğunu gösterdik."
Ekibin usta üyesi Changxi Zheng, FontCode'un gizli ileti gönderme amaçlı kullanımın yanı sıra, şirketlerin işine yarayabilecek uygulamalarının da önemini vurguluyor: Belgelerin görüntüsü bozulmadan kullanım haklarının korunmasını, QR kodu veya başka metadata türlerinin gömülmesini sağlıyor. Bu teknikte bir metin belgesine gizlenebilecek veri miktarı, belgedeki metnin uzunluğuna bağlı oluyor. Çoğu yazı tipi ile kullanılabiliyor ve diğer belgeye veri gizleme yöntemlerinden farklı olarak çoğu belge tipi ile kullanılabiliyor. Ayrıca belgenin dosya türü değiştirilse ya da çıktısı alınsa bile gizli ileti yitirilmiyor. Fakat eğer şifreli metni bir editörde açıp kopyalarak, başka bir metin editörü penceresine yapıştırırsanız, iletiyi yitiriyorsunuz.
Program gizlenecek mesajı bir bit dizisine çevirdikten sonra, bir tamsayı dizisine çeviriyor. Her bir tamsayı, normal metindeki beş harflik bir bloğa atanıyor.FontCode'u kullanarak veri gömmek için gizli bir ileti ve bir taşıyıcı belge veriyorsunuz. Program gizlenecek mesajı 0 ve 1'lerden oluşan bir bit dizisine (ASCII veya Unicode) çevirdikten sonra, bir tamsayı dizisine çeviriyor. Her bir tamsayı, normal metindeki beş harflik bir bloğa atanıyor. Daha sonra normal metindeki her bir harfin yerine, kod kitabındaki değiştirilmiş hâli yerleştiriliyor. Her beşlideki değiştirilmiş hâldeki harflerin kod kitabındaki konum numaralarının toplamı, o beşliye atanmış olan tamsayı ediyor.
Gizli iletiyi açığa çıkarmak için ise işlem tersinden yapılıyor. Dijital bir dosyadan veya akıllı telefon ile çekilmiş bir fotoğraftan, FontCode harfleri orijinalleriyle karşılaştırarak değiştirilmiş harfleri belirliyor ve kod kitabından iletiyi oluşturuyor.
Karşılaştırma, evrişimli sinirsel ağlar (İng. convolutional neural networks - CNN) kullanılarak yapılıyor. Vektör çizimli (PDF olarak kaydedilenler ya da Illustrator gibi programlarla hazırlananlar gibi olan) yazı tiplerinde söz konusu belirleme işlemi kolay, çünkü şekil ve yol tanımları bilgisayar tarafından okunabilir oluyor. Ama PNG, IMG gibi pikselli yazı tiplerinde iş o kadar basit değil. Aydınlatma farkı, değişik kamera açıları, gürültü ve netlikteki bozukluklar dolayısıyla karşılaştırma ve oyuntusu farklı olanları belirleme işlemi güçleşiyor.
"Hello World" iletisinin "Bilbo was very rich..." şeklinde başlayan metnin içince gizlenme ve gizli metnin yeniden oluşturulma sürecini gösteren şema. "Hello World" iletisinin "Bilbo was very rich..." şeklinde başlayan metnin içince gizlenme ve gizli metnin yeniden oluşturulma sürecini gösteren şema.Ekip bu güçlüğü aşabilmek için 1700 yıllık Çinli Kalan Teoremi'nden yararlandıklarını belirtiyor. Bu teorem, bilinmeyen bir sayının, birkaç farklı bölenle bölümünden kalan sayılara bakarak bulunmasını sağlar. Efsaneye göre eski bir Çin hükümdarı, ordusundaki asker sayısını bulmak için tüm orduyu önce 3 kişilik, sonra 5 kişilik, sonra da 7 kişilik gruplara ayırır ve her seferinde grup dışı kalan asker sayısına bakarmış. Buna göre, ordudaki toplam asker sayısını hesaplarmış. Zheng, FontCode için bu teoremden nasıl yararlandıklarını şöyle anlatıyor: "Üç tane bilinmeyen değişken olsun. Üç tane lineer eşitlik ile bunların üçünü de bulabilmeniz gerekir. Eğer eşitlik sayısını üçten beşe çıkarırsanız, bu beş eşitlikten herhangi üçünü bildiğiniz sürece, üç bilinmeyeni yine bulursunuz." Çinli Kalan Teoremi'ni kullanarak, harflerdeki değişikliklerin %25'i tanınamasa bile iletilerin yeniden oluşturulabileceğini araştırmacılar gösterdi.
Kaynak ve İleri Okuma
- Chang Xiao et al, FontCode, ACM Transactions on Graphics (2018). DOI: 10.1145/3152823 , https://arxiv.org/pdf/1707.09418.pdf https://arxiv.org/abs/1707.09418
- TechXplore, "Researchers hide information in plain text" https://techxplore.com/news/2018-05-plain-text.html
- Columbia Üniversitesi, "FontCode: Hiding information in plain text, unobtrusively and across file types"" https://www.cs.columbia.edu/2018/fontcode-hiding-information-in-plain-text-unobtrusively-and-across-file-types/
Etiket
Projelerimizde bize destek olmak ister misiniz?
Dilediğiniz miktarda aylık veya tek seferlik bağış yapabilirsiniz.
Destek Ol
Yorum Yap (0)
Bunlar da İlginizi Çekebilir

12 Şubat 2018
Faraday Kafesindeki Bilgisayardan Veri Çalmak Mümkün

23 Mart 2019
Sabit Sürücüler Ortam Sesini Alabiliyor




11 Mayıs 2019
Kuantum İlkelerine Dayalı Bir Sanal Para Önerildi
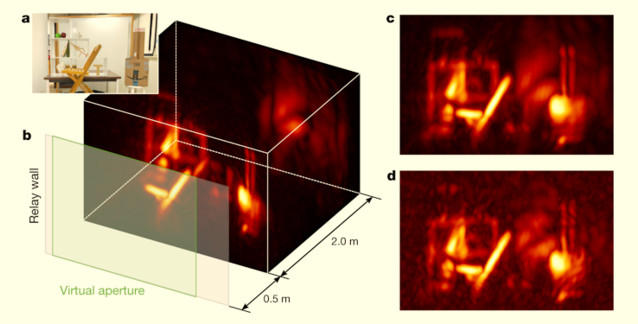
06 Ağustos 2019
Görüş Alanı Dışı Görüntülemede İlerleme Kaydedildi

Bağış Yap, Destek Ol!
Projelerimizde bize destek olmak istersen
Patreon üzerinden aylık veya tek seferlik
bağışta bulunabilirsin.
En Çok Okunan
Bu Ay Öne Çıkanlar



2
İnsanlık Uygarlığı Neden Bu Kadar Geç Keşfetti?

Gürkan Akçay
Boğaziçi Üniversitesi - Yazar / Editör
E-Bülten Üyeliği
Duyurulardan e-posta ile haberdar olmak istiyorum.