
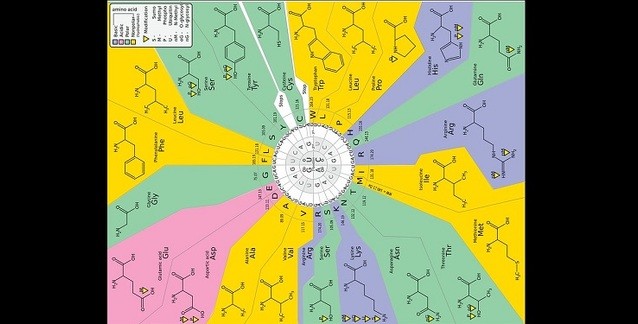
Genetik kodun keşfi, modern biyolojideki en önemli ilerlemelerden biriydi. Ama bir DNA kodunda protein diziliminden daha fazlası vardır; DNA uç-birleştirme (ayıklama), yerelleştirme, katlama ve yönetme sinyalleri taşır ki bunlar çoğunlukla protein-kodlayan dizilimin içine gömülü olur. Bu sayıda Itzkovitz ve Alon, genetik kodda bulunan özgün “64’ten 20’ye” eşlemenin, protein-kodlayan bölgelerin bu fazladan bilgiyi taşıması için optimize olmuş olabileceğini ortaya koyuyor ve bu özelliğin, çerçeve kayması hatalarının olumsuz etkilerini en aza indirme seçiliminin ek kazancı olarak evrilmiş olabileceğini ileri sürüyor.
İlk Kod Kuramlarının “Vahşi Batı”sı ve Virgülsüz Kod
Kodun öyküsündeki ilk ışık parıltısı, Dounce (1952) tarafından o zamanlar sıra dışı bir fikir olan nükleotidlerin sıralamasının polipeptid zincirlerindeki amino asitlerin sıralamasını belirlediğinin ortaya atılmasıyla gelmişti. Eşlenme için açıklama sunan DNA’nın çift-sarmal yapısının keşfinden sonra (Watson & Crick 1953), genetik ifadelenmenin sırlarını çözme yarışı başladı. Gamow (1954) bir “anahtar-kilit” mekanizması önerdi; buna göre, dört nükleotidden oluşan DNA’daki “delikler”e amino asitler özgün (spesifik) olarak bağlanıyordu. Deliğin şekli, ona hangi amino asidin bağlanabileceğini belirleyerek, DNA diziliminin özgün bir amino asit dizilimi kodlamasına olanak tanıyordu. Her bir deliği oluşturan dört bazın ikisi bütünleyiciydi ki bu da, her bir amino asidin bir baz üçlüsü tarafından tanımlandığına işaret ediyordu. Dikkatli analizler bu “elmas kod”un (İng. diamond code) en fazla 20 farklı amino asit kodlayabileceğini açığa çıkararak, kuramı özellikle çekici kıldı. Ama (şu anda bizim verdiğimiz adla) kodonların kesiştikleri düşünüldü: Proteindeki konum-1’de bulunan amino asidi kodlayan üç nükleotid, amino asit-2’yi kodlayan nükleotidlerin ikisini içerecekti. Bu da mümkün olan amino asit dizilimlerini kısıtlayacaktı (Gamow 1954).
Fakat Gamow’un sonuçlarını (Gamow 1954; Gamow et al. 1956) analiz eden Crick ve çalışma arkadaşları, doğada böyle kısıtlamalar bulunmadığını gün yüzüne çıkardı (Crick et al. 1957). Aynı yıl Brenner (1957) kesişen bir üçlü kodun olasılık dışı tutulabileceğini gösterdi. Ama alternatif, kesişmeyen üçlülerin olduğu bir koda sahip olmak, doğru okuma çerçevesini seçme ve zorunlu tutma problemini gündeme getiriyordu. Diziyi ard-arda çevirmekle (translasyon) problemin çözülebileceğini anladıkları hâlde, başlatma kodonlarından haberleri olmadığından, Crick ve çalışma arkadaşları bir “virgülsüz kod” önerdi (Crick et al. 1957). Virgülsüz kod, keyfî amino asit dizilimleri için kodlamaya izin veriyor ve sadece tek bir okuma çerçevesinde okunabiliyordu; yanlış çerçevede okumaya yönelik herhangi bir girişim derhal anlamsız (İng. nonsense) olarak tanımlanacaktı. Bu, çok fazla sayıda anlamsız kodon kullanılarak başarılıyordu; öyle ki çerçeve-dışı herhangi bir dizilim ancak onlardan oluşacaktı. Elmas kod durumunda olduğu gibi, bir virgülsüz kod tarafından kodlanabilecek en fazla amino asit sayısı tam olarak 20 idi; doğada kullanılan amino asitlerin sayısını veren baştan çıkarıcı bir tesadüf.
Tahminde bulunma oyunu bu kadarla kalmadı. Sinsheimer (1959), A ve C’nin G ve U gibi eşdeğer olduğu sadece iki harflik bir kod önerdi. Bu şemada 20 farklı amino asit kodlamak için en az beş baz gerekiyordu. Ertesi yıl Yčas (1960), proteinlerde farklı amino asit bollukları ve RNA’da farklı baz bollukları sergileyen çeşitli virüslerin deneysel gözlemlerine dayalı bir hipotez ileri sürdü. Bu fikre göre, tekil nükleotidler (nükleotid üçlüleri değil) amino asit kodluyordu ama nükleotid dizilimi gereken bilginin sadece bir kısmını içeriyordu. Üç nükleotidden fazlasının bir amino asidi kodladığı başka kodlar da akıldan geçirildi: Golomb (1962) virgülsüz olan ve çevrimi çok güvenilir kılan ilave özelliklere sahip bir altılı kod önerdi. Genetik kod konusundaki bu erken döneme ait kuramsal yaklaşımlar Hayes (1998) tarafından özetlendi.
Fazlalıklı Kodun Optimal Özellikleri
Nirenberg ve çalışma arkadaşları tarafından hakiki genetik kodun keşfi (Nirenberg & Matthaei 1961; Nirenberg 2004), kuramsal tahminlere (spekülasyonlara) bir son verdi ve virgülsüz kod ile öteki erken dönem kuramlarının çabucak reddedilmesine yol açtı. Kodun fazlalıklı olması şaşırtıcı bir şeydi ve ilgi odağı oldu. Örneğin, aynı amino asidin birkaç benzer kodona atandığı sistemi tanımlayan aile kutuları ve titreme kuralları (Crick 1966) belirlendi. Kodun, rastgelelikten uzak görünen başka çarpıcı özellikleri açığa çıkarıldı. Woese benzer kodonların, benzer kimyasal özellikli, özellikle de benzer kutupsal gereklilikli amino asitlere atandığını gözlemledi (Woese 1965b; Woese et al. 1966a). Kodun, yanlış-çevrim hatalarının etkisini en aza indirmek için optimize olduğunu ileri sürdü. Bu hatalar, bir kodon, bir kökteşe-yakın (İng. near-cognate) antikodonlu tRNA vasıtasıyla çevrildiğinde gerçekleşir. Genetik kodun, çevrimsel yanlış-okuma hatalarının etkisini en aza indirecek şekilde optimize olduğu bulgusu, Haig & Hurst (1991) tarafından istatistiksel olarak niceliklendirildi ve taraflı (İng. biased) yanlış-çevrim ve mutasyon hesaba katılarak daha da güçlendirildi (Freeland & Hurst 1998).
Kodun nasıl evrildiği hakkında çok sayıda tahmin yapıldı (Osawa et al. 1992; Knight et al. 1999, 2001a; Di Giulio 2004). Bir “donmuş rastlantı” mıydı (Crick 1968)? Eğer öyleyse, neden bu kadar işe yarar özelliklere sahipti? Kodun erken dönemdeki evrimini etkileyen çeşitli etkenler önerildi:
- Kod, mutasyonların (Sonneborn 1965) veya çevrim hatalarının (Woese 1965a) etkisini en aza indirme gibi belirli işlevleri optimize etme seçilim baskısı altında evrilmiştir;
- Amino asit biyosentezi yolaklarının evrilmesiyle tutarlı olarak, koddaki amino asit sayısı evrimsel süreçte artmıştır (Wong 1975);
- Amino asitler ile kısa nükleik asit dizilimleri arasındaki doğrudan kimyasal etkileşimler, başlangıçta genetik koddaki karşılık gelme atamalarına yol açmıştır (Woese et al. 1966b).
Bu hipotezler birbirlerini geçersizleştirmiyordu ve hepsinin Crick’in donmuş rastlantı hipotezini (İng. frozen accident hypothesis) olasılık dışı bırakması için destekleri vardı. Yukarıda ele alındığı gibi, belirli işlevler için kod optimizasyonuna ilişkin kanıtlar mevcuttur ve bazı amino asitlerin proteinlerde kullanım sıklığı azalırken, diğerlerininkinin arttığına ilişkin işaretler vardır (Jordan et al. 2005, ama ayrıca bkz. Hurst et al. 2006; Wong 2005); bu da bazı amino asitlerin genetik koda nispeten yakın zamanda eklendiğini akla getirir. Arginin bağlayan rastgele RNA’lar, arginin kodonlarında artmaktadır (Knight & Landweber 2000) ve izolösin amino asidini bağlayan en basit RNA molekülleri, onunla bağlantılı olan kodon ve antikodonlara çok benzer dizilim motiflerine sahiptir (Lozupone et al. 2003).
Varyant kodların keşfi (Barrell et al. 1979; Fox 1987; Knight et al. 2001a), evrilebilirlik ile evrensellik arasındaki bağlantıyı daha da kafa karıştırıcı hâle getirmiştir. Bir yandan, genetik kodların evrilebileceğini kanıtlarlar; öte yandan, eğer kolayca evrilebiliyorlarsa, neden tüm varyasyonlar küçüktür? Erken dönemdeki evrim sırasındaki geniş çaplı yatay gen aktarımının, hem optimalliğe doğru evrimi hem de genetik kodun evrenselliğe yakınlığını açıklayabileceği, yakın zamanda ileri sürülmüştür (Vetsigian et al. 2006).
Optimalliğin Çerçevesini Kaydırmak
Peki ama eğer kod bazı işlevler için optimize olduysa, acaba kodun yine optimalleştiği başka, daha az belli işlevler de var mıdır? Çerçeve kayması mutasyonları önemli olabilir çünkü kaynakları boşa harcayan ve zehirli de olabilen, işlevsiz proteinlerle sonuçlanırlar. Kaynakların boşa harcanmasını en aza indiren bir yol, hatanın ardından uzatmayı mümkün olduğunca çabuk sonlandırmaktır. Çerçeve kayması hatalarının etkisinin evrimsel süreçte en aza indirildiğine ilişkin bazı biyo-enformatik ipuçları bulunmaktadır. Çoğu organizmada (hepsinde olmasa da), kodon kullanım sıklıklarının, eğer çerçeve-dışı okunursa durdurma kodonlarına katkı yapabilen kodonlardan yana olduğu gözlemlenmiştir (Seligmann & Pollock 2004).
Eğer bir çerçeve kayması hatasından sonra hızlı sonlandırma optimizasyonu genetik kodun kendi içine inşa edilmişse, bir optimal kod neye benzer? Tüm anlamsız (İng. nonsense) kodonların bugünün terminolojisindeki “durdurma kodonları”na karşılık geliyor olarak yorumlandığı Crick’in virgülsüz kodu, bu açıdan mükemmel koddur: bir çevrimsel (translasyonel) çerçeve kaymasının hemen ardından çevrimi (translasyonu) durdurur. Ancak, böylesine aşırı bir optimizasyon pahalıya patlar. Virgülsüz kodda hiçbir amino asit için eşanlamlı kodonlar olmadığından, nokta mutasyonların büyük çoğunluğu anlamsız (İng. nonsense) kodonlar doğurur; bunlar da yok edici (İng. null) mutasyonlara eşdeğerdir. Bu da mutasyonel yükü epeyce yükseltir. Gerçek genetik kodda, yaklaşık olarak 20 nokta mutasyondan sadece biri yeni bir durdurma kodonuyla sonuçlanır (Osawa et al. 1992) ve öteki 19 tanenin çoğu (muhtemelen değişik özellikli) işlevsel proteinler verir. O hâlde soru, genetik kodun başka işlevler için optimizasyonu korunurken, bir çerçeve kayması hatasından sonra hızlı sonlandırma için optimize edilip edilemeyeceğidir.
Kısıtlar Olarak Bilinen Özellikleri Olan Genetik Kodun Optimalliği
Genome Research dergisinin bu sayısında Itzkovitz ve Alon, genetik kodun optimize olmuş gibi göründüğü iki yeni özelliğin ilginç keşfi konusunu yazdı. Gerçek genetik kodu, yanlış-çevrim veya mutasyon açısından eşit ölçüde optimize olmuş tüm diğer kodların topluluğuyla karşılaştırdılar (bu istatistiksel yaklaşım hakkında daha fazlası için bkz. Alff-Steinberger 1969; Haig & Hurst 1991; Freeland & Hurst 1998). Farklı amino asitlerin, topluluktaki kodon atamaları değişirken, kullanım sıklıklarının sabit olduğunu varsayarak, bir çerçeve kayması hatası gerçekleştikten sonra çevrim kesilene dek katılan amino asitlerin sayısını en aza indirmede, gerçek kodun diğer olası kodlardan çok daha iyi olduğunu buldular. O hâlde, Itzkovitz ve Alon tarafından yapılan bu yeni gözlem, başka tür çevrim hatalarına ve mutasyonlara karşı sağlam olma gereksinimiyle kod üzerine getirilen kısıtlarla modifiye edilmiş olarak, Crick’in bir virgülsüz kod kuramı temelinin hayata dönüşü olarak görülebilir. Elde ettikleri sonucun bir diğer olası yorumu ise amino asit kullanımının çerçeve kayması hatalarının etkilerini azaltmaya uyduğudur; alternatif genetik kodlar, onlarla birlikte-uyumlanmış farklı bir amino asit kullanımına sahip olurdu. Amino asit kullanımının oldukça esnek olduğu ve örneğin GC içeriğinden etkilendiği önceden ortaya konmuştu (Knight et al. 2001b).
Itzkovitz ve Alon bir başka, oldukça beklenmedik optimallik çeşidi öneriyor: Kod, keyfî ilave bilgi yani protein-kodlayan dizilimlerde amino asit sıralamasından başka bilgi, kodlamak için yüksek düzeyde optimaldir. Ek bilgi kodlamak için optimallik, kodlayan bölgelerin nükleotid diziliminde bulunan bilinen sinyaller düşünülürse, özellikle önemli ve alakalıdır. Bunlar arasında RNA uç-birleştirme sinyalleri vardır; bunlar müstakbel proteinin amino asit dizilimiyle ve ayrıca çevrim (translasyon) teçhizatı tarafından tanınan sinyallerle birlikte nükleotid diziliminde kodlanır (Cartegni et al. 2002), Örneğin, genellikle dur sinyalleri olarak okunan az sayıda kodon, eğer mRNA ipliğinde özel bir bağlamda görülürlerse, ender kullanılan selenosistein amino asidi olarak çevrilirler (Fox 1987). Nükleozomların DNA’da nerede konumlanması gerektiği hakkındaki bilgi de baz diziliminde bulunur (Yuan et al. 2005; Segal et al. 2006). RNA ikincil yapısı için olan dizilimler de, protein-kodlayan dizilimlerde çok bol bulundukları yakın zamanda anlaşılan bir başka bilgi kaynağıdır (Zuker & Stiegler 1981; Shpaer 1985; Konecny et al. 2000; Katz & Burge 2003).
İlginçtir, kodun hem bilgi kodlama hem de çerçeve kayması sonrası çevrim kesme için optimal yapısı, aynı kök nedenden yani durdurma kodonlarının bir dizilim içinde kolayca saklı kalabilmesi olgusundan türemiş görünmektedir. Örneğin UGA durdurma kodonu, NNU|GAN’dan sadece bir çerçeve kayması uzaklıktadır; GAN kodonları protein dizilimlerinde çok yaygın olan Asp ve Glu kodlar. Benzer biçimde, UAA ve UAG çerçeve kaymasına uğrayarak NNU|AAN ve NNU|AGN verebilir (AAN kodonları Asn veya Lys kodlar ve AGN Ser veya Arg verir). Glu, Lys, Asp, Ser ve Arg genomda nispeten yaygın olan amino asitlerdir; dolayısıyla bu üç amino asitten birinin bir kodonunun yanlış-okunmasından bir durdurma kodonu doğma olasılığı çok yüksektir. Bir durdurma kodonunun bir çerçeve kayması kullanarak bu şekilde “gizlenebileceği” gerçeği, bir durdurma kodonu içermek durumunda kalan (er ya da geç doğacak bir problem) bir sinyal diziliminin bile durdurma kodonunun sık kullanılan bir amino asidi kodladığı iki okuma çerçevesinden biri kullanılarak, protein dizilimi içinde kodlanabilmesi anlamına gelir.
Gizli mesajları kodlama yetisi, kodun fazlalıklı olmasının doğrudan bir sonucudur. Tıpkı genetik kod gibi dilin de, örneğin İngilizcenin önemli ölçüde fazlalığı vardır; yani bilgi kuramsal bakış açısına göre belli bir mesaj iletmek için gerekenden daha fazla harf ve sözcük kullanılır. Başka bir deyişle, İngilizce bir cümlenin bilgi içeriği, aynı uzunlukta bir Latin harfleri ve noktalama işaretleri dizisiyle kodlanabilecek olandan daha azdır. Bu fazlalıklılık, birden fazla mesajın paralel taşınımına olanak tanır; şüpheli gözükmeyen iletiler şeklinde “kamuflajlanmış” gizli mesajlar göndermek için insanlık tarihinin çeşitli zamanlarında kullanılmış olan bir özelliktir bu (steganografi). Aydınlatıcı bir örnek, “Sherlock Holmes” öyküsünün şu cümlesinde bulunabilir (Conan Doyle, 1893, The Adventure of the Gloria Scott):
“The supply of game for London is going steadily up. Head-keeper Hudson, we believe, has been now told to receive all orders for fly-paper and for preservation of your hen pheasant’s life.”
İlkinden başlayarak her üçüncü sözcük okunduğunda (ve birkaç noktalama işareti eklendiğinde), gizli mesaj ortaya çıkar: “The game is up. Hudson has told all. Fly for your life.” Dilin veya kullanılan kodun fazlalıklılığı düştükçe, bir ileti içinde böyle ek mesajlar iletmek giderek zorlaşır.
Biri ötekinden daha belli ve ayrıntılı olmak üzere iki mesajı aynı anda iletme fikri, bir nükleotid diziliminde, bir amino asit dizilimi için olan bir şablonun beraberinde kodlamayan bilgi vermeye benzer. Ancak, asıl mesajın kamuflaj olarak kullanıldığı insan iletişiminden farklı olarak, doğada bu yaklaşımın kullanılma nedeni elbette gizlilik değildir. Kaynakları verimli şekilde kullanma seçilim baskısı, genetik kodun bu özelliği benimsemesine neden olmuş olabilir. Peki acaba ilave kodlamayan bilgi kodlayabilmek, kodun erken dönemdeki evriminde gerçekten açık bir avantaj olmuş mudur? Ek bilgi kodlayabilme yetisi ile çerçeve kayması hatalarının ardından çevrimsel sonlandırmanın optimalliği özelliği arasındaki korelasyon, kaynakların boşa harcanmasının en aza indirilmesi seçiliminin çevrimi verimli şekilde sonlandıran kodlardan yana olduğu ve kodun ek bilgi taşıma yetisinin bir yan ürün olduğu bir olası evrimsel senaryo sunar. Bu ikinci özellik ancak sonradan, ek karmaşık düzenleyici programlar ve düzenleyici motifler gelişmeye başlayınca önemli hâle gelmiş olabilir. Olası bir istisna, RNA ikincil yapısını durağanlaştırmak (stabilize etmek) için olan dizilimleri içerme yetisidir. Protein-kodlama işlevlerinin paralelinde bu yetiye de sahip olan RNA molekülleri, bu yeti bakımından daha verimsiz olan RNA’lara karşı bir avantaj elde etmiş olabilir.
Genetik kodun işlevleri hakkında daha fazla şey öğrendikçe, genetik koddaki yozluktan (dejenerelikten) tek işlevi optimize edecek şekilde değil de, eşzamanlı olarak birkaç farklı işlevin bir kombinasyonunu optimize edecek şekilde faydalanıldığı daha açık hâle gelmektedir. Kodun yapısına daha derinlemesine baktıkça, daha başka hangi ilginç özellikler taşıyor olabileceğini merak ediyoruz. Son yıllarda genetik koda ilişkin kavrayışımız büyük ölçüde artmış olsa da, keşfedilmeyi bekleyen ilginçlikler var gibi görünmektedir.- Evolution and multilevel optimization of the genetic code - T. Bollenbach & K. Vetsigian & R. Kishony (Genome Res. 2007. 17: 401-404) https://genome.cshlp.org/content/17/4/401.full
Dilediğiniz miktarda aylık veya tek seferlik bağış yapabilirsiniz.
Destek OlBunlar da İlginizi Çekebilir





En Çok Okunan
Bu Ay Öne Çıkanlar



İnsanlık Uygarlığı Neden Bu Kadar Geç Keşfetti?

E-Bülten Üyeliği
Duyurulardan e-posta ile haberdar olmak istiyorum.